Why UTBMS and LEDES Don’t Work As Well As They Should, And How AI Can Help

The Uniform Task-Based Management System (UTBMS) can seem like the holy grail when it comes to understanding legal spend, but unfortunately, like most systems designed by humans, it’s prone to human error.
This article was created to help you better understand what UTMBS and LEDES codes are, how relying on them is negatively impacting your legal spend forecasting, and what you can do to change that.
What Exactly are UTBMS and LEDES?
UTBMS is a set of codes that classify legal work. Created in the 1990s along with the electronic LEDES invoice file format, UTBMS is used to code descriptions of legal work in LEDES invoices. UTBMS codes and their associated costs can be aggregated up to a matter, vendor, or practice area level.
In theory, armed with a historical dataset of UTBMS-coded legal invoices, legal professionals should be able to answer that age-old question: how much should a particular piece of legal work really cost? Unfortunately, they often fail to do so.
When UTBMS and LEDES Codes Fail
While UTBMS codes were created with the goal of bringing order and predictability to legal spend, there is a fatal flaw in the system. Relying on individual lawyers to code work means that creating an accurate, standardized dataset is impossible because lawyers interpret and use the codes differently.
This failure isn’t the lawyers’ fault, it’s a natural part of being human. Humans are notoriously bad at classification and tend to be slower, less accurate, and less consistent at applying codes to data than machines.
The LEDES invoice format also has its shortcomings. UTBMS codes can be linked to each description of legal work on LEDES invoices, but UTBMS codes are not required by the LEDES format, leading to data gaps.
So how can we make use of our treasure trove of historical legal spend data if line items are coded in a subjective, non-standard way? And how can we ensure that 100% of our legal spend is coded, filling the data gaps?
We’re here to help you untangle this messy problem.
Why Categorizing Legal Spend is So Important
We’ve all heard it said that the facts of each legal case are unique. This can make it difficult to budget for an individual matter since unforeseen bumps in the road lead to uncertainty. It also complicates the task of comparing vendor performance across matters since no two matters are the same. While that is true at the level of individual cases, at the level of an organization, it’s typical to have repeatable matter types where average costs can be determined for each phase of work.
A common language is needed to make sense of the phases of a legal matter and the typical costs associated with them. That’s where UTBMS codes come in. UTBMS codes define the different phases of work in common matter types, including litigation, mergers and acquisitions (M&A), and intellectual property (IP). They also include task codes which further break out the work in each phase.
UTBMS codes help us break down individual matters into their component parts, assign a total spend to each, and use that to determine the average spend per phase and task.
UTBMS codes are reported at the line item level in LEDES invoices: outside counsel provide line item descriptions explaining every piece of work they have done for their client and assign a UTBMS task code to each.
UTBMS codes also enable the systematic application of outside counsel guidelines. In a world without coded legal spend data, in-house attorneys must review invoices line-by-line to determine whether billed work violates the guidelines.
This is a time-consuming, manual task and far from the best use of your busy attorneys’ time. When legal spend is coded, outside counsel guidelines can each be assigned a code and automatically checked, removing tedious work from your attorneys’ desks while ensuring you are not paying for items outside of the agreed scope of work.
From predicting future legal spend to comparing the value received from outside counsel and consistent billing guideline application, achieving legal spend management goals is not possible unless we have a true understanding of our legal spend data. Categorizing legal spend gives us the insight needed to confidently manage spend.
How UTBMS Coding Creates Issues for In-House Legal
Imagine you’re a busy senior associate in an Am Law 100 firm. You’ve just finished a 12-hour day working complex cases for your clients. You’re about to close your computer and head out for a well-deserved dinner when you realize, ‘Oh no, I forgot to do my time entries!’ Before you rush out the door, you fire some data into your time entry system.
Do you take time to look up whether the strategy calls you had with Acme Co about the upcoming expert witness deposition should be classified with UTBMS task code L120 Analysis/Strategy, L330 Depositions, or L420 Expert Witnesses? Probably not.
The reality is that every lawyer could code this work differently and probably ten other ways as well.
Now imagine that you’re a legal ops professional at Acme Co. You’re a reporting whizz and see an opportunity to delve into your rich trove of law firm-coded UTBMS data to understand the average cost per phase for your patent litigation claims.
You might think you’re getting accurate numbers, but the reality is that the data is no good – it’s non-standardized, subjective, and not truly representative of cost. So, what was the point of busy outside counsel coding all those time entries?
Brightflag’s Data Highlights the Limits and Failures of UTBMS
Brightflag is the legal operations platform corporate legal teams rely on to manage spend, matters, and vendors. Brightflag’s platform includes a patented AI engine that reads and classifies invoice line items. Brightflag’s AI engine has classified millions of invoice line items.
Often, the LEDES invoices line items processed by Brightflag contain UTBMS codes inputted by outside counsel. Brightflag has compared the AI engine’s UTBMS coding of invoice line items with the UTBMS codes used by outside counsel on the same line items.
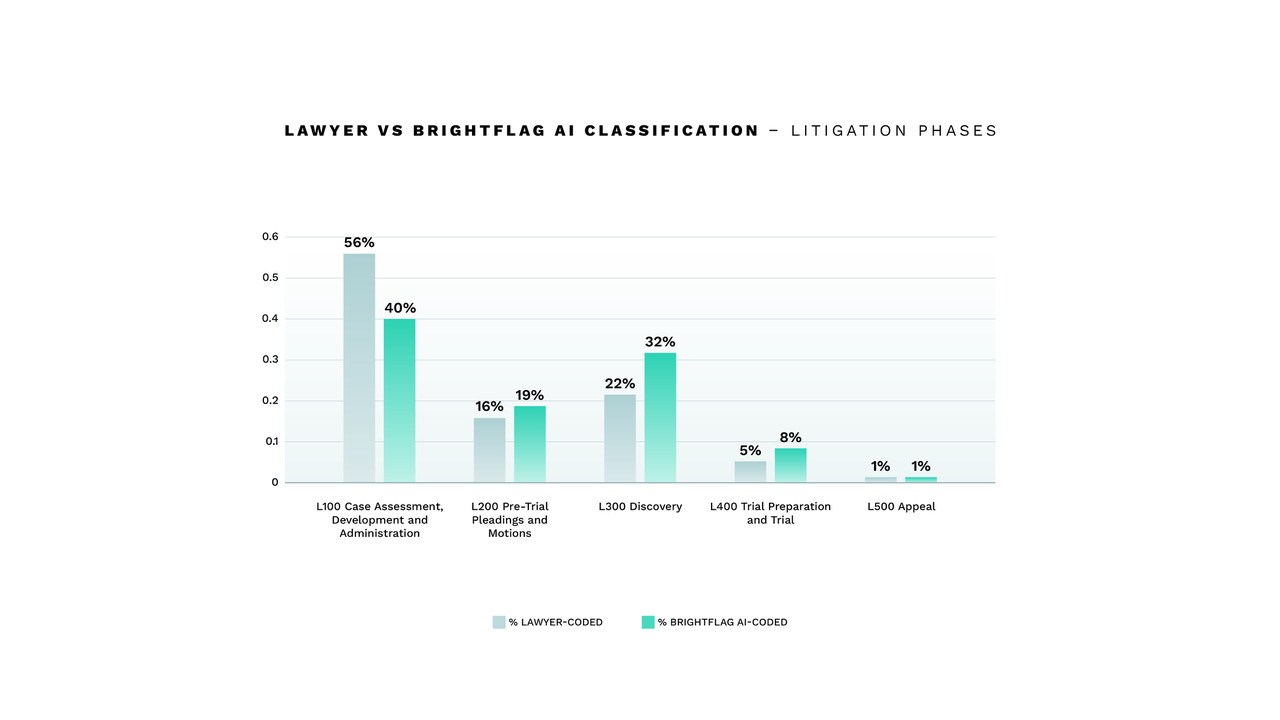
Brightflag’s analysis of litigation invoice line items illustrates the issue of lawyer coding. It shows that lawyers over-rely on the phase code L100 Case Assessment, Development, and Administration. This can make it difficult to understand true costs for heavy-spend areas such as pre-trial pleadings and motions and discovery because line items that, in fact, relate to pre-trial or discovery work are coded as preliminary case assessment work.
Overuse of L100 codes by lawyers complicates assessments of matter resourcing. Preliminary case assessment and strategy work is typically performed by more senior lawyers, such as partners, while later-stage work on discovery and other areas should be resourced by more junior associates.
If pre-trial, discovery, or trial work is performed by senior lawyers and incorrectly coded to the L100 phase, it is harder to spot that the work has not been resourced at the appropriate level.
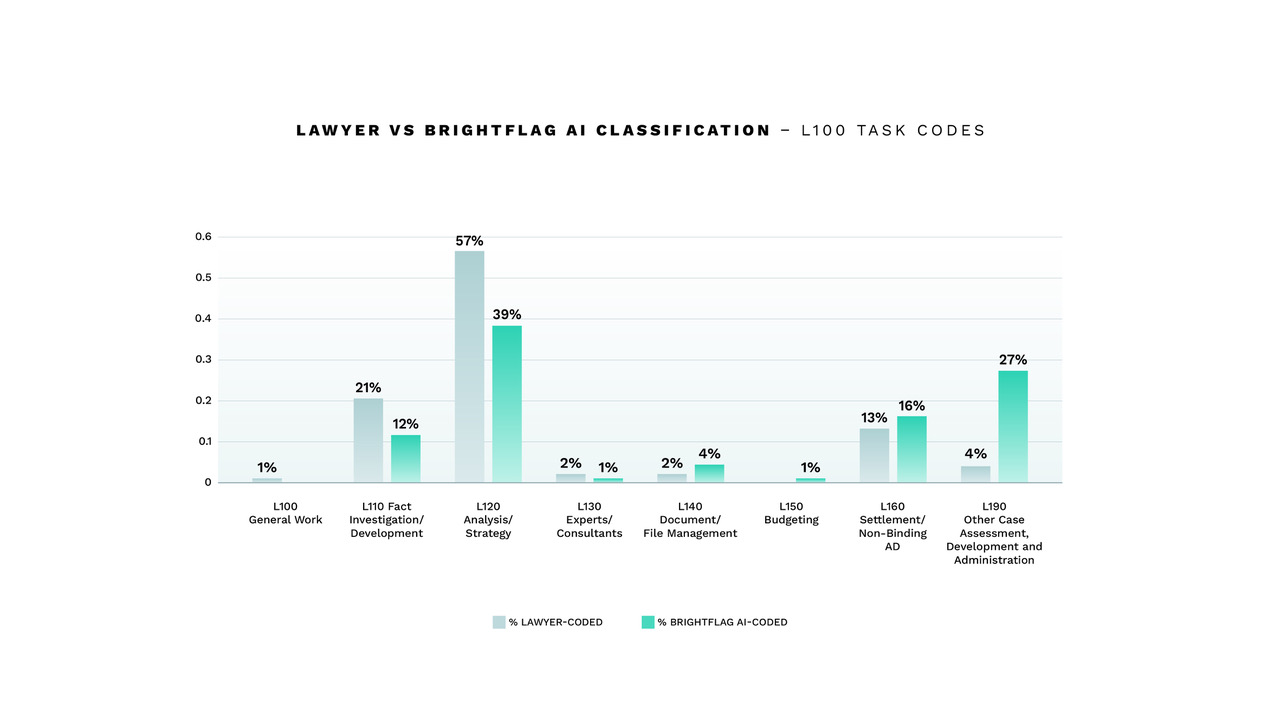
Digging deeper into task codes, we can see that lawyers use task codes L110 Fact Investigation/Development and L120 Analysis/Strategy within L100 most often.
According to the American Bar Association, the task code L120 Analysis/Strategy should be used for strategizing for a case, including initial legal research for case assessment and for developing a basic case strategy.
Brightflag’s analysis shows that, in practice, the L120 task code is overused for strategy and research performed over the entire course of the case. This means that some costs are incorrectly assigned to this task code.
Due to the overuse of the L120 Analysis/Strategy code, the true costs for pre-trial, discovery, and trial strategy are not recorded by lawyers, making it difficult to assess whether the work was performed at the appropriate level of seniority.
The ABA also states that task code L110 Fact Investigation/Development covers investigating the facts of a matter and reviewing documents to learn the facts of the case, but does not cover not document production, which falls under the phase L300 Discovery.
It’s well-understood in the legal community that discovery, and document production, in particular, is an area of high spend for litigation matters. Understanding the true cost of document production is important for deciding if this work can be automated or outsourced to lower-cost legal service providers. It’s also important to ensure that this work is done by junior timekeepers where possible to keep costs low.
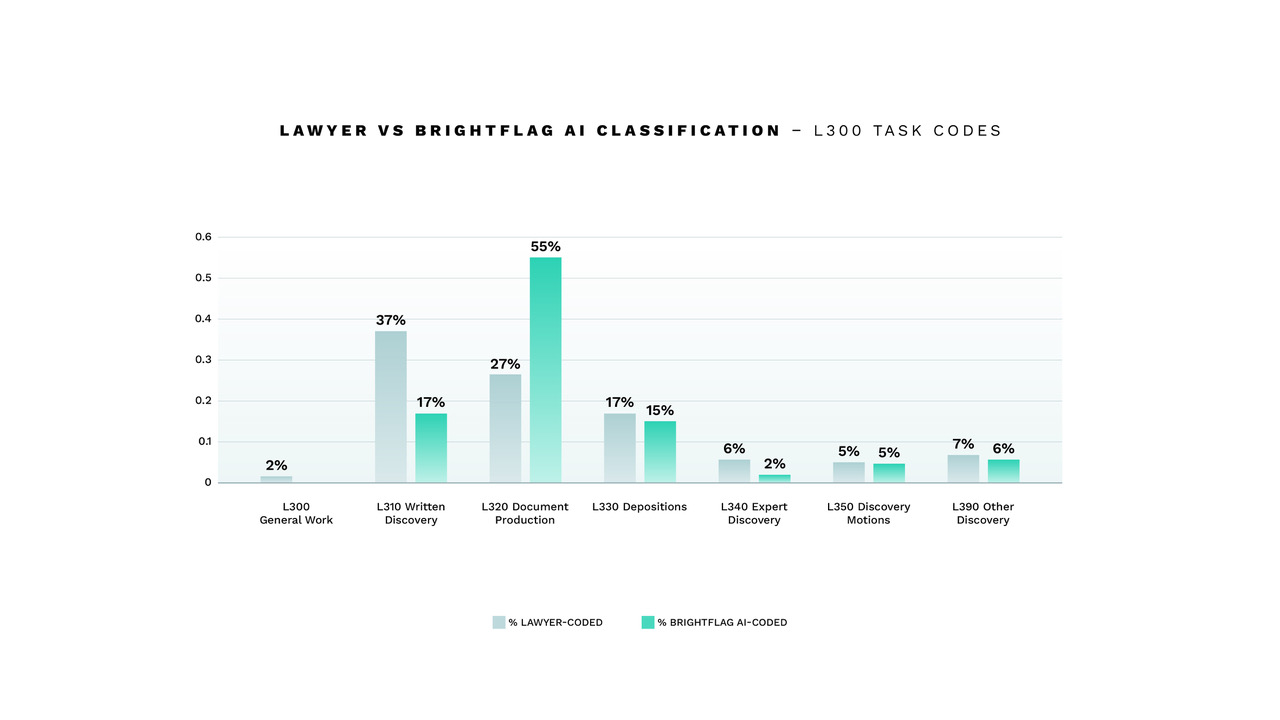
Brightflag’s analysis shows that lawyers over-use the preliminary L100 codes and do not allocate enough spend to other areas such as document production for discovery. This leads to an inaccurate representation of legal spend per phase and task and clouds the analysis of appropriate matter resourcing.
The LEDES Data Gap
The LEDES file format made great strides in bringing legal invoices into the digital world when it was first introduced 30 years ago. However, three decades on, some issues have emerged with LEDES invoices.
Firstly, the LEDES invoice file format does not require UTBMS codes on each line item. An analysis of litigation invoices processed by Brightflag revealed that 30% of all LEDES line items do not contain a UTBMS code. This large gap in UTBMS data on LEDES invoices further adds to the problem of incomplete and inaccurate data on legal spend.
In addition, 10% of all litigation line items analyzed by Brightflag included instances of block billing. Block billing is when a lawyer describes multiple tasks and activities in one invoice line item. Only one UTBMS code can be assigned per line item in the LEDES file format, so outside counsel must assign a single code to describe various types of work, creating further gaps in the accuracy of LEDES invoice data.
The gap in LEDES data presents a problem for gaining full visibility into legal spend. However, because of the subjective coding of invoice line items by lawyers, the answer to the LEDES data gap problem is not requiring lawyers to code 100% of line items. This would only make the problem worse by leading to more inaccurately and inconsistently coded data.
The Black Box of PDF Invoices
No matter whether you work for a US-headquartered company with a vast majority of matters on home soil or a multinational with legal work across dozens of countries, the truth is that you will never have 100% of your invoices submitted in LEDES file format.
From boutique or sole-practitioner firms without billing systems to counsel in non-US countries that are required by tax law to submit PDF invoices, some percentage of spend will be submitted as PDF invoices.
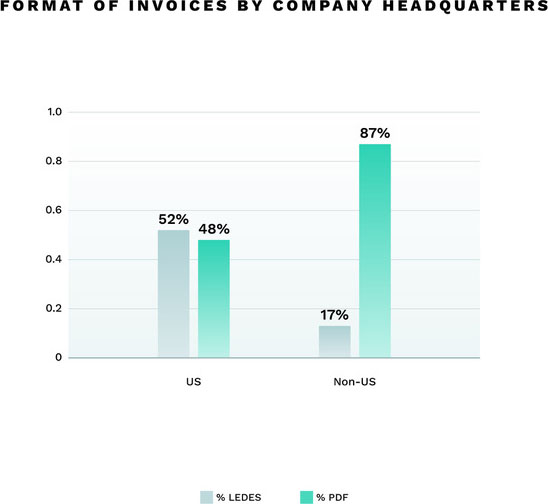
An analysis of Brightflag’s data shows that 48% of all invoices for US-headquartered customers are submitted as PDFs, while 87% are submitted in PDF format for non-US headquartered customers.
Most legal spend management systems do not have a way to parse information provided in PDFs. This creates a significant gap when it comes to understanding your legal spend data.
The Limits of UTBMS and LEDES
The legal industry has created a powerful set of UTBMS codes to help legal teams understand their spend. However, the traditional approach to coding means there is no way to use UTBMS to create accurate, data-backed insights for strategic decision-making.
To make matters worse, not all LEDES invoices contain UTBMS coding, and the issue of PDF invoices creates further data gaps. So, what can be done to help legal teams truly understand and predict legal spend?
The Way Forward: AI-powered UTBMS Classification
AI has driven the world forward by applying advanced computing to complex problems.
The problem of accurately classifying legal spend is no different. AI can be used to ingest legal line item descriptions, parse the activities and tasks performed, and to apply UTBMS codes to the descriptions in a standardized way.
By doing so, AI transcends the problem of subjectivity by always coding similar work the same way. This AI-driven approach to UTBMS classification removes the need for lawyer input, saving time for your busy outside counsel and ensuring there are no data gaps: with AI classification, you can rest assured that every line item is coded.
In addition, new Optical Character Recognition (OCR) technology can be used to extract line item narratives on PDF invoices, meaning the black box of PDF invoices is opened, giving you visibility into 100% of your legal spend and drawing an accurate picture of costs.

Conclusion
UTBMS codes provide a powerful opportunity to bring order to the messy field of understanding and forecasting future legal costs. UTBMS codes allow us to break legal spend down into matter phases and tasks and to find out how much work on our most common matter types actually costs. Delving into our treasure trove of historical spend data, UTBMS codes are the key to predicting what future legal work should cost, enabling us to act more strategically.
But there’s a catch: even though your busy outside counsel spend their precious time coding legal line items, a system that relies on human coding will always fall victim to subjectivity and non-standardization. Add to that the fact that LEDES invoices don’t require UTBMS codes on every line item and that some portion of spend will always be housed in PDF invoices, and it makes the goal of generating an accurate picture of your spend impossible.
Luckily, there is a way forward: AI-classified line items which unlock the true power of the UTBMS codes to create accurate, standardized spend classification – meaning you can be confident in using your data to super-charge your strategic decision-making.
Want to learn more about how Brightflag’s AI can overcome issues with UTBMS and LEDES, giving you an accurate picture of your legal spend? Contact us today.
Share:


Sarah Scales

Director of Content Marketing at Brightflag


